我们正在运行一个进程,它有一个消耗大量内存的缓存。但是缓存中的对象数量在执行过程中保持稳定,而内存使用量却在无限增长。
我们已经运行java飞行记录器来尝试猜测发生了什么。
在那个报告中,我们可以看到usedheap大约是usedsize的一半,对此我找不到任何解释。
jvm退出并转储outofmemory报告,您可以在这里找到:https://frojasg1.com/stackoverflow/20210423.outofmemory/hs_err_pid26210.log
下面是整个java飞行记录器报告:https://frojasg1.com/stackoverflow/20210423.outofmemory/test.7z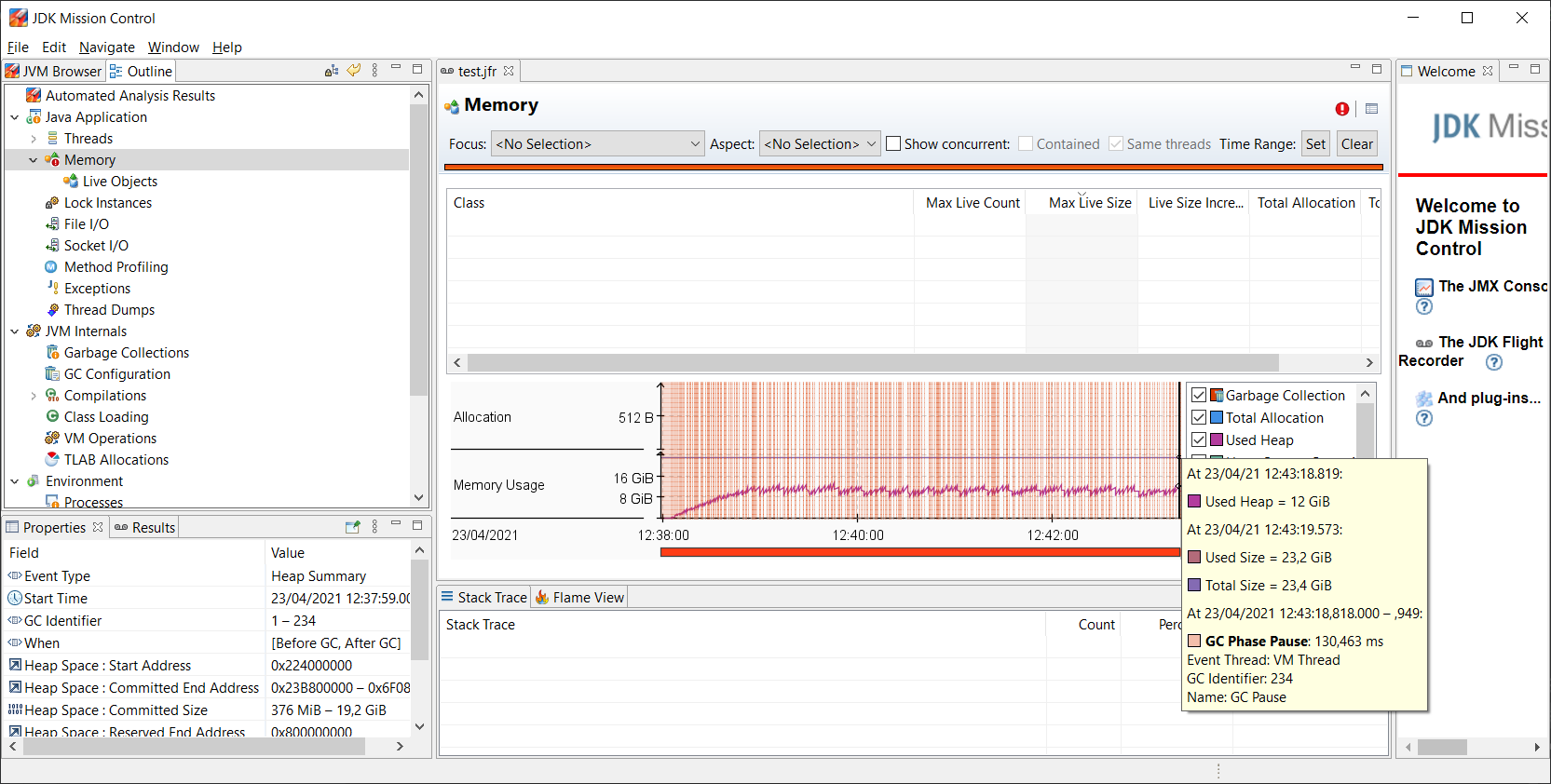
有人知道为什么会有这样的回忆吗?
也许我得换个问题。。。并问:为什么堆中几乎有10gb的已用内存没有使用?
2条答案
按热度按时间50few1ms1#
日志文件显示:
因此,jvm已经通过一个
mmap系统调用,操作系统拒绝了。当我查看更多的日志文件时,很明显g1gc本身正在请求更多的内存,看起来它正在尝试扩展heap1。
我可以想出几个可能的原因
mmap失败:操作系统可能没有交换空间来支持内存分配。
jvm可能已达到每个进程的内存限制(在unix/linux上,这是作为ulimit实现的。)
如果您的jvm运行在docker(或类似的)容器中,那么您可能已经超出了容器的内存限制。
这不是一个“正常”的oome。这实际上是jvm的内存需求与操作系统提供的内存之间的不匹配。
它可以在操作系统级别解决;i、 e.通过移除或增加限制,或添加更多交换空间(或可能更多ram)。
也可以通过减少jvm的最大堆大小来解决这个问题。这将阻止gc尝试将堆扩展到不可持续的大小2。这样做也可能导致gc更频繁地运行,但这比应用程序过早地死于可避免的oome要好。
1-在g1gc诊断方面有更多经验的人可能能够从崩溃转储中分辨出更多信息,但在我看来这是正常的堆扩展行为。没有明显的迹象表明有一个“巨大”的物体被创造出来。
2-确定可持续的大小实际上包括分析整个系统的内存使用情况,查看可用的ram和交换资源以及限制。这是一个系统管理问题,而不是编程问题。
euoag5mw2#
也许我得换个问题。。。并问:为什么堆中几乎有10gb的已用内存没有使用?
您看到的是当前分配给堆的内存与设置的堆限制之间的差异。jvm实际上并不预先从操作系统请求所有堆内存。相反,它要求更多的内存增量。。。如果需要。。。在主要gc运行结束时。
因此,虽然堆的总大小看起来约为24gb,但实际分配的内存却远远小于这个值。
正常情况下,这很好。gc向os请求更多内存,并将其添加到相关池中,供内存分配器使用。但在这种情况下,操作系统无法满足要求,g1gc拔掉了插头。