我有一个项目,不同类型的作业在spark中运行,我们将数据转换为spark Dataframe ,并在这些 Dataframe 上应用foreach lambda,使它们并行执行。现在对于一个作业,我需要在作业开始时存储一些变量,并在不同的API,db调用中使用它们,所以我想到使用ThreadLocal来存储这些变量,然后在需要时从同一个ThreadLocal中选择。
但不久之后,我意识到spark lambda forEach正在创建不同的线程,因此ThreadLocal无法工作,所以我转移到InheritedThreadLocal,在那里我也无法获取变量。这里有一个演示代码来显示我在做什么
class Util {
static InheritedThreadLocal<Map> threadLocal = new InheritedThreadLocal();
}
class Job {
void runJob() {
Utils.threadLocal.set(key1, value1)
val list = someListData.asInstanceOf[RDD[Long]]
printThreadInfo1()
list.forEach(key => {
doSomething()
})
}
void doSomething() {
printThreadLocal2()
Utils.threadLocal.get(key1); // returns null value
}
}这里InheritedThreadLocal在doSomething内部返回null值,所以我尝试打印线程Info这里是printThreadInfo1()=〉threadId=1和ThreadName = main的结果,但对于printThreadInfo2()内部,打印不同的信息为threadId=34 threadName=Executor task launch worker for task 7。0在阶段0中。0(TID 7)
我认为在lambda下创建的线程应该是主线程的子线程,因此InheritedThreadLocal应该工作,但看起来它们是不同的线程。
这里有没有我做错的地方,或者有什么方法可以在不同的spark员工之间共享这些变量?
1条答案
按热度按时间ddrv8njm1#
您看到的不同线程是预期的行为。
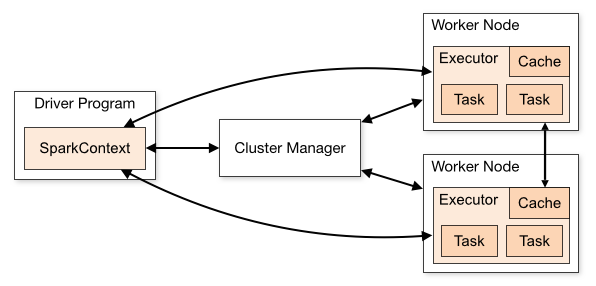
方法
runJob()在驱动程序上执行,而方法doSomething()是在其中一个工作节点上执行的任务。这意味着这段代码可能在另一个JVM中运行,因此ThreadLocals将不起作用。Spark docs中有一个图示说明了设置:
你可以使用broadcasts来代替ThreadLocals。This answer展示了一个简单的示例如何广播JavaMap。