JDK并发工具类源码学习系列——ConcurrentSkipListMap
更多文章请阅读:JDK并发工具类源码学习系列目录。
ConcurrentSkipListMap在JDK并发工具类使用范围不是很广,它是针对某一特殊需求而设计的——支持排序,同时支持搜索目标返回最接近匹配项的导航方法。一般情况下开发者很少会使用到该类,但是如果你有如上的特殊需求,那么ConcurrentSkipListMap将是一个很好地解决方案。
Java Collections Framework中另一个支持排序的Map是TreeMap,两者都是有序的哈希表,但是TreeMap是非线程安全的,当然可以使用Collections.synchronizedSortedMap将TreeMap进行包装,但是性能方面就显得捉急了,毕竟多个线程一起读都需要加锁是不太合理的,至少做到读写分离呀。但是从JDK1.6开始我们就多了一个选择:ConcurrentSkipListMap。这是一个支持高并发度的有序哈希表,并且是无锁的,可在多线程环境下替代TreeMap。
下面我们从几个方面来分析ConcurrentSkipListMap的实现,主要分析ConcurrentSkipListMap的数据结构以及如何实现高并发且无锁读写的。
- 实现原理
- 数据结构
- 常用方法解读
- 使用场景
实现原理
ConcurrentSkipListMap不同于TreeMap,前者使用SkipList(跳表)实现排序,而后者使用红黑树。相比红黑树,跳表的原理比较容易理解,简单点说就是在有序的链表上使用多级索引来定位元素。下面是简单看看SkipList的原理:
现在假设我们拥有一个有序的列表,如果我们想要在这个列表中查找一个元素,最优的查找算法应该是二分 查找了,但是链表不想数组,链表的元素是非连续的,所以无法使用二分查找来进行高效查找,那么抛开其他查找算法不说,最低效的算法就是从链表头部开始遍历,直至找到要查找的元素,虽说低效但是确是最大化使用了链表的优势——遍历。那么我们有没有可能同时提高查找效率,而且还使用链表的优势呢?跳表就是我们想要的查找算法。其实说白了跳表就是一种多级索引,通过索引链表中的部分值来确定被查找的值所处的范围。
跳表分为多层,层数越高,最高层元素越少,查找时也会越快,但是所占空间也就越多,所以跳表是用空间换时间(可见如果大量数据不是太适用,毕竟内存是有限的)。
跳表结构示意图:
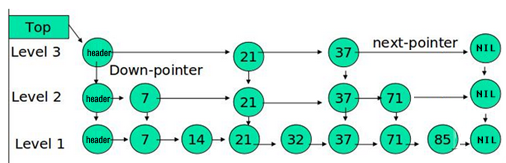
可以看见每一层都是一个有序的链表,而且是原始链表的子集,最底层(level1)是完整的链表结构,越往上链表的元素越少,同时查找也就越快。当我们需要查找一个元素时,会从跳表的最上层链表开始查询,定位元素的大致位置,然后通过向下指针再在下层查找。
跳表查找示意图:
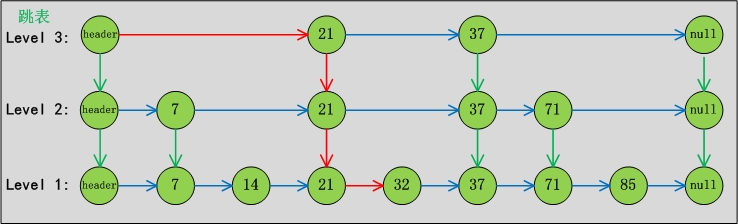
上图是从跳表中查找32的过程。
跳表的查找时间复杂度是:O(log(n)),更多详细关于跳表的介绍可参考:http://kenby.iteye.com/blog/1187303
数据结构
ConcurrentSkipListMap在原始链表的基础上增加了跳表的结构,所以需要两个额外的内部类来封装链表的节点,以及跳表的节点——Node和Index。
Node:链表的节点
static final class Node<K,V> {
final K key;
volatile Object value;
volatile Node<K,V> next;
}同ConcurrentHashMap的Node节点一样,key为final,是不可变的,value和next通过volatile修饰保证内存可见性。
Index:跳表的节点
static class Index<K,V> {
final Node<K,V> node;
final Index<K,V> down;
volatile Index<K,V> right;
}Index封装了跳表需要的结构,首先node包装了链表的节点,down指向下一层的节点(不是Node,而是Index),right指向同层右边的节点。node和down都是final的,说明跳表的节点一旦创建,其中的值以及所处的层就不会发生变化(因为down不会变化,所以其下层的down都不会变化,那他的层显然不会变化)。
Node和Index内部都提供了用于CAS原子更新的AtomicReferenceFieldUpdater对象,至于该对象的原理下面是不会深入研究的。
常用方法解读
从API文档可以看到ConcurrentHashMap的方法很多,很多都是一些为了方便开发者的提供的,例如subMap(K, boolean, K, boolean)、headMap(K, boolean)、tailMap(K, boolean)等都是用来返回一个子视图的方法。这里我们主要看看能够表达ConcurrentHashMap实现原理的三个方法:put(K, V)、get(Object)、remove(Object, Object)。
在介绍这三个方法之前,我们先看一个辅助工具方法:comparable(Object)。
/** * If using comparator, return a ComparableUsingComparator, else * cast key as Comparable, which may cause ClassCastException, * which is propagated back to caller. */
// @By Vicky:将key封装成一个Comparable对象
private Comparable<? super K> comparable(Object key) throws ClassCastException {
if (key == null)
throw new NullPointerException();
// @By Vicky:有两种封装方法,如果在构造时指定了comparator,则使用comparator封装key
// 如果没有指定comparator,则key必须是一个继承自Comparable接口的类,否则会抛出ClassCastException
// 所以ConcurrentSkipListMap的key要么是继承自Comparable接口的类,如果不是的话需要显示提供comparator进行比较
if (comparator != null)
return new ComparableUsingComparator<K>((K)key, comparator);
else
return (Comparable<? super K>)key;
}从上面那个辅助方法可以看到ConcurrentSkipListMap的key必须要能够进行比较,可以有两种方式提供比较方法,代码注释中已提到。
put(K, V)
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
// @By Vicky:实际调用内部的doPut方法
return doPut(key, value, false);
}
/** * @By Vicky: * 三个参数,其中onlyIfAbsent表示是否只在Map中不包含该key的情况下才插入value,默认是false */
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
// 将key封装成一个Comparable对象,便于直接与其他key进行比较
Comparable<? super K> key = comparable(kkey);
for (;;) {
// 从跳表中查找最接近指定key的节点:该节点的key小于等于指定key,且处于最底层
Node<K,V> b = findPredecessor(key);
Node<K,V> n = b.next;// b的下一个节点,新节点即将插入到b与n之间
// 准备插入
for (;;) {
if (n != null) {// n==null则说明b是链表的最后一个节点,则新节点直接插入到链表尾部即可
Node<K,V> f = n.next;// n的下一个节点
if (n != b.next) // inconsistent read 此处增加判断,避免链表结构已被修改(针对节点b)
break;;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);// 将n从链表移除,b和f分别为n的前继节点与后继节点
break;
}
// 这里如果v==n说明n是一个删除标记,用来标记其前继节点已被删除,即b已被删除
// 查看helpDelete()的注释
if (v == n || b.value == null) // b is deleted
break;
// 比较key,此处进行二次比较是避免链表已发生改变,比如b后面已被插入一个新的节点
// (findPredecessor时已经比较过b的next节点(n)的key与指定key的大小,因为n的key>指定key才会返回b)
int c = key.compareTo(n.key);
if (c > 0) {// 如果指定key>n的key,则判断下一个节点,直到n==null,或者指定key<n的key
b = n;
n = f;
continue;
}
if (c == 0) {// 相等,则更新value即可,更新失败,就再来一次,一直到成功为止
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
// 创建一个节点,next指向n
Node<K,V> z = new Node<K,V>(kkey, value, n);
// 将b的next指向新创建的节点,则新的链表为:b-->new-->n,即将新节点插入到b和n之间
if (!b.casNext(n, z))
break; // restart if lost race to append to b
// 随机计算一个层级
int level = randomLevel();
// 将z插入到该层级
if (level > 0)
insertIndex(z, level);
return null;
}
}
}代码中已经附上了大量的注释,这里再简单的梳理下流程。首先put()方法是调用内部的doPut()方法。Comparable< ? super K&> key = comparable(kkey);这一句将key封装成一个Comparable对象,上面已经介绍了comparable这个方法。接着进入到死循环,循环第一步是调用**findPredecessor(key)**方法,该方法返回一个key最接近指定key的节点(最接近指的是小于等于),该节点是处于最底层的,下面介绍下这个方法的逻辑。
/** * @By Vicky: * 在跳表中查找节点的key小于指定key,且处于最底层的节点,即找到指定key的前继节点 * 基本逻辑是从head(跳表的最高层链表的头结点)开始自右开始查找,当找到该层链表的最接近且小于指定key的节点时,往下开始查找, * 最终找到最底层的那个节点 */
private Node<K,V> findPredecessor(Comparable<? super K> key) {
if (key == null)
throw new NullPointerException(); // don't postpone errors
for (;;) {
Index<K,V> q = head;// head是跳表的最高层链表的头结点
Index<K,V> r = q.right;// head的右边节点
for (;;) {// 循环
if (r != null) {// r==null说明该层链表已经查找到头,且未找到符合条件的节点,需开始往下查找
Node<K,V> n = r.node;// r的数据节点
K k = n.key;// r的key,用于跟指定key进行比较
if (n.value == null) { // n的value为null,说明该节点已被删除
if (!q.unlink(r))// 将该节点从链表移除,通过将其(n)前置节点的right指向其(n)的后置节点
break; // restart
r = q.right; // reread r 移除value==null的n节点之后,继续从n的下一个节点查找
continue;
}
if (key.compareTo(k) > 0) {// 比较当前查找的节点的key与指定key,如果小于指定key,则继续查找,
// 大于等于key则q即为该层链表最接近指定key的
q = r;
r = r.right;
continue;
}
}
// 到这里有两种情况:1)该层链表已经查找完,仍未找到符号条件的节点 2)找到一个符合条件的节点
// 开始往下一层链表进行查找
Index<K,V> d = q.down;
if (d != null) {// 从下层对应位置继续查找
q = d;
r = d.right;
} else// 如果无下层链表则直接返回当前节点的node
return q.node;
}
}
}
// @By Vicky:将当前节点的right指向succ的right指向的节点,即将succ从链表移除
final boolean unlink(Index<K,V> succ) {
return !indexesDeletedNode() && casRight(succ, succ.right);
}该方法的查找逻辑是:从head(跳表的最高层链表的头结点)开始自右开始查找,当找到该层链表的最接近且小于指定key的节点时,往下开始查找,最终找到最底层的那个节点。具体的代码可以看注释,应该说的挺明白的了,针对PUT方法,这个方法返回的节点就是将要插入的节点的前继节点,即新节点将插到该节点后面。下面是查找的示意图。
findPredecessor查找示意图:
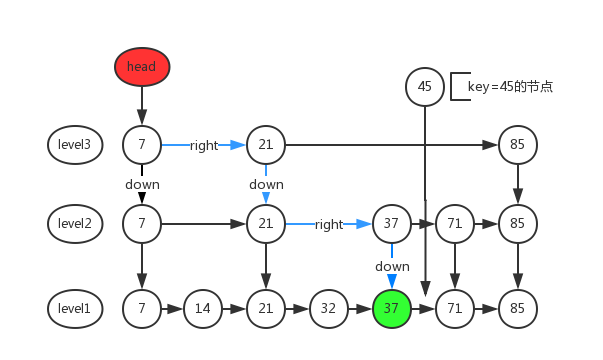
findPredecessor()介绍完,我们返回doPut()继续往下走。通过findPredecessor()返回节点b,获取b的next节点赋值n,接着进入死循环。判断n是否为null,n==null则说明b是链表的最后一个节点,则新节点直接插入到链表尾部即可,下面我们来看看n!=null的情况。
Node<K,V> f = n.next;// n的下一个节点
if (n != b.next) // inconsistent read 此处增加判断,避免链表结构已被修改(针对节点b)
break;;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);// 将n从链表移除,b和f分别为n的前继节点与后继节点
break;
}
// 这里如果v==n说明n是一个删除标记,用来标记其前继节点已被删除,即b已被删除
// 查看helpDelete()的注释
if (v == n || b.value == null) // b is deleted
break;这里首先判断在这段时间内b的next是否被修改,如果被修改则重新获取。再接着判断n和b是否被删除。这里说下helpDelete()方法,这个方法比较绕。
void helpDelete(Node<K,V> b, Node<K,V> f) {
/* * Rechecking links and then doing only one of the * help-out stages per call tends to minimize CAS * interference among helping threads. */
if (f == next && this == b.next) {
// 判断当前节点是否已添加删除标记,未添加则添加删除标记
if (f == null || f.value != f) // not already marked
appendMarker(f);
else
// 如果已添加删除标记,则将b的next指向f的next
// 因为当前节点已添加了删除标记,所以这里的f只是一个标记:value==本事的节点,其next才是链表的下一个节点
// 这里应该是remove方法相关,涉及到ConcurrentSkipListMap的删除方式
b.casNext(this, f.next);
}
}
/** * @By Vicky:为当前节点增加一个删除标记 * 将当前节点的next指向一个新节点,该新节点的next指向f,所以从结构是:当前-->new-->f * 新节点的value就是他自己,参见Node(Node<K,V> next)构造函数 * 即删除标记就是将一个节点与其next节点之间插入一个value就是本事的节点 */
boolean appendMarker(Node<K,V> f) {
return casNext(f, new Node<K,V>(f));
}介绍helpDelete()之前,先简单介绍ConcurrentSkipListMap是如何删除一个节点的,其实ConcurrentSkipListMap删除一个节点现将该节点的value值为NULL,然后再为这个节点添加一个删除标记,但是这个操作有可能失败,所以如果一个节点的value为NULL,或者节点有一个删除标记都被认为该节点已被删除。appendMarker()就是用来添加删除标记,helpDelete()是用来将添加了删除标记的节点清除。添加标记和如何清除在代码中的注释已经说的很清楚了,就不多说了。继续看doPut()。
// 比较key,此处进行二次比较是避免链表已发生改变,比如b后面已被插入一个新的节点
// (findPredecessor时已经比较过b的next节点(n)的key与指定key的大小,因为n的key>指定key才会返回b)
int c = key.compareTo(n.key);
if (c > 0) {// 如果指定key>n的key,则判断下一个节点,直到n==null,或者指定key<n的key
b = n;
n = f;
continue;
}
if (c == 0) {// 相等,则更新value即可,更新失败,就再来一次,一直到成功为止
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value
}
// else c < 0; fall through这几句是考虑当我们找到一个最接近指定key的节点之后有可能链表被修改,所以还需要进行二次校验,从b开始往右边查找,直至找到一个key大于指定key的节点,那么新的节点就插入到该节点前面。
// 创建一个节点,next指向n
Node<K,V> z = new Node<K,V>(kkey, value, n);
// 将b的next指向新创建的节点,则新的链表为:b-->new-->n,即将新节点插入到b和n之间
if (!b.casNext(n, z))
break; // restart if lost race to append to b
// 随机计算一个层级
int level = randomLevel();
// 将z插入到该层级
if (level > 0)
insertIndex(z, level);
return null;这几句就是创建一个新的节点,并插入到原链表中,所有的修改操作都是使用CAS,只要失败就会重试,直至成功,所以就算多线程并发操作也不会出现错误,而且通过CAS避免了使用锁,性能比用锁好很多。
请继续阅读后续部分~~~
版权说明 : 本文为转载文章, 版权归原作者所有 版权申明
原文链接 : https://blog.csdn.net/hqshaozhu/article/details/49507615
内容来源于网络,如有侵权,请联系作者删除!