文章16 | 阅读 7187 | 点赞0
kafka:topic为什么要进行分区?副本机制是如何做的?
kafka为什么要在topic里加入分区的概念?如果没有分区,topic中的segment消息写满后,直接给订阅者不是也可以吗?
Kafka可以将主题划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。另外,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力:

Kafka的设计也是源自生活,好比是为公路运输,不同的起始点和目的地需要修不同高速公路(主题),高速公路上可以提供多条车道(分区),流量大的公路多修几条车道保证畅通,流量小的公路少修几条车道避免浪费。收费站好比消费者,车多的时候多开几个一起收费避免堵在路上,车少的时候开几个让汽车并道就好了,嗯……
顺便说一句,由于消息是以追加到分区中的,多个分区顺序写磁盘的总效率要比随机写内存还要高(引用Apache Kafka – A High Throughput Distributed Messaging System的观点),是Kafka高吞吐率的重要保证之一。
为了保证数据的可靠性,Kafka会给每个分区找一个节点当带头大哥(Leader),以及若干个节点当随从(Follower)。消息写入分区时,带头大哥除了自己复制一份外还会复制到多个随从。如果随从挂了,Kafka会再找一个随从从带头大哥那里同步历史消息;如果带头大哥挂了,随从中会选举出新一任的带头大哥,继续笑傲江湖。

详见下:卡夫卡的副本机制。
观点2:
这里其实有2个问题,可以逐一回答
1.kafka为什么要在topic里加入分区的概念? topic是逻辑的概念,partition是物理的概念,对用户来说是透明的。
producer只需要关心消息发往哪个topic,而consumer只关心自己订阅哪个topic,并不关心每条消息存于整个集群的哪个broker。 为了性能考虑,如果topic内的消息只存于一个broker,那这个broker会成为瓶颈,无法做到水平扩展。
所以把topic内的数据分布到整个集群就是一个自然而然的设计方式。
Partition的引入就是解决水平扩展问题的一个方案。
如同我在Kafka设计解析(一)里所讲,每个partition可以被认为是一个无限长度的数组,新数据顺序追加进这个数组。
物理上,每个partition对应于一个文件夹。一个broker上可以存放多个partition。
这样,producer可以将数据发送给多个broker上的多个partition,consumer也可以并行从多个broker上的不同paritition上读数据,实现了水平扩展
2.如果没有分区,topic中的segment消息写满后,直接给订阅者不是也可以吗 ?
“segment消息写满后”,consume消费数据并不需要等到segment写满,只要有一条数据被commit,就可以立马被消费
segment对应一个文件(实现上对应2个文件,一个数据文件,一个索引文件),一个partition对应一个文件夹,一个partition里理论上可以包含任意多个segment。
所以partition可以认为是在segment上做了一层包装。
这个问题换个角度问可能更好,“为什么有了partition还需要segment”。
如果不引入segment,一个partition直接对应一个文件(应该说两个文件,一个数据文件,一个索引文件),那这个文件会一直增大。
同时,在做data purge时,需要把文件的前面部分给删除,不符合kafka对文件的顺序写优化设计方案。
引入segment后,每次做data purge,只需要把旧的segment整个文件删除即可,保证了每个segment的顺序写,
参考:https://www.zhihu.com/question/28925721
卡夫卡的副本机制
由于Producer和Consumer都只会与Leader角色的分区副本相连,所以kafka需要以集群的组织形式提供主题下的消息高可用。kafka支持主备复制,所以消息具备高可用和持久性。
一个分区可以有多个副本,这些副本保存在不同的broker上。每个分区的副本中都会有一个作为Leader。当一个broker失败时,Leader在这台broker上的分区都会变得不可用,kafka会自动移除Leader,再其他副本中选一个作为新的Leader。
在通常情况下,增加分区可以提供kafka集群的吞吐量。然而,也应该意识到集群的总分区数或是单台服务器上的分区数过多,会增加不可用及延迟的风险。
创建副本的2种模式——同步复制和异步复制
kafka动态维护了一个同步状态的副本的集合(a set of In-Sync Replicas),简称ISR。
在这个集合中的节点都是和leader保持高度一致的,任何一条消息只有被这个集合中的每个节点读取并追加到日志中,才会向外部通知说“这个消息已经被提交”。
只有当消息被所有的副本加入到日志中时,才算是“committed”,只有committed的消息才会发送给consumer,这样就不用担心一旦leader down掉了消息会丢失。
消息从leader复制到follower, 我们可以通过决定producer是否等待消息被提交的通知(ack)来区分同步复制和异步复制。
如果等待ack则为同步,如果不需要等待所有follower复制完成即回传ack则为异步模式。
同步复制:
1.producer联系zk识别leader
2.向leader发送消息
3.leadr收到消息写入到本地log
4.follower从leader pull消息
5.follower向本地写入log
6.follower向leader发送ack消息
7.leader收到所有follower的ack消息
8.leader向producer回传ack
异步复制:
和同步复制的区别在于,leader写入本地log之后,
直接向client回传ack消息,不需要等待所有follower复制完成。
卡夫卡支持副本模式,那么其中一个broker里的挂掉,一个新的leader就能通过ISR机制推选出来,继续处理读写请求。
Kafka集群partition replication默认自动分配分析
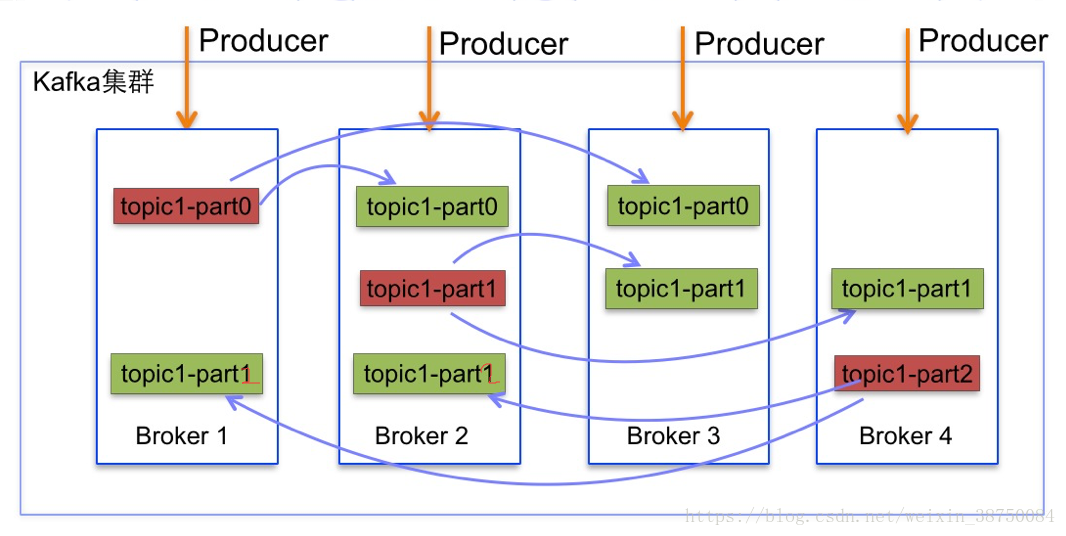
下面以一个Kafka集群中4个Broker举例,创建1个topic包含4个Partition,2 Replication;数据Producer流动如图所示:
(1)

(2)当集群中新增2节点,Partition增加到6个时分布情况如下:
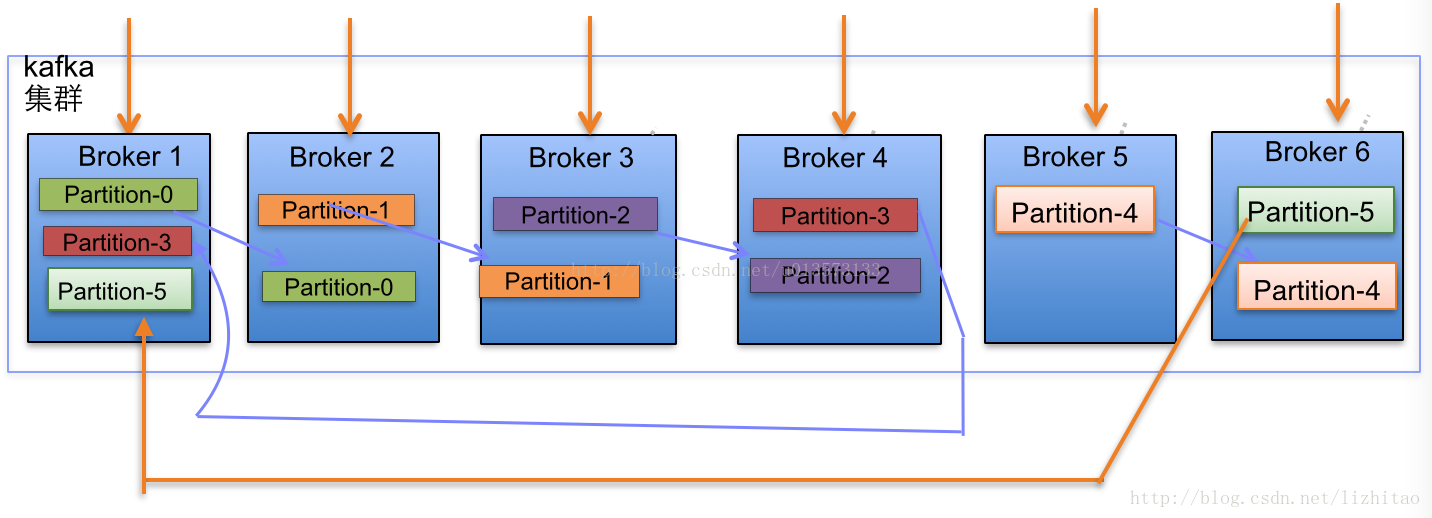
副本分配逻辑规则如下:
- 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
- 上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
- 上述图中每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
副本分配算法如下:
- 将所有N Broker和待分配的i个Partition排序.
- 将第i个Partition分配到第(i mod n)个Broker上.
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
版权说明 : 本文为转载文章, 版权归原作者所有 版权申明
原文链接 : https://blog.csdn.net/ywl470812087/article/details/105210041
内容来源于网络,如有侵权,请联系作者删除!