RocketMQ原理(3)——水平扩展及负载均衡详解
https://zhuanlan.zhihu.com/p/25140744
RocketMQ是一个分布式具有高度可扩展性的消息中间件。本文旨在探索在broker端,生产端,以及消费端是如何做到横向扩展以及负载均衡的。
Broker端水平扩展
Broker负载均衡
Broker是以group为单位提供服务。一个group里面分master和slave,master和slave存储的数据一样,slave从master同步数据(同步双写或异步复制看配置)。
通过nameserver暴露给客户端后,只是客户端关心(注册或发送)一个个的topic路由信息。路由信息中会细化为message queue的路由信息。而message queue会分布在不同的broker group。所以对于客户端来说,分布在不同broker group的message queue为成为一个服务集群,但客户端会把请求分摊到不同的queue。
而由于压力分摊到了不同的queue,不同的queue实际上分布在不同的Broker group,也就是说压力会分摊到不同的broker进程,这样消息的存储和转发均起到了负载均衡的作用。
Broker一旦需要横向扩展,只需要增加broker group,然后把对应的topic建上,客户端的message queue集合即会变大,这样对于broker的负载则由更多的broker group来进行分担。
并且由于每个group下面的topic的配置都是独立的,也就说可以让group1下面的那个topic的queue数量是4,其他group下的topic queue数量是2,这样group1则得到更大的负载。
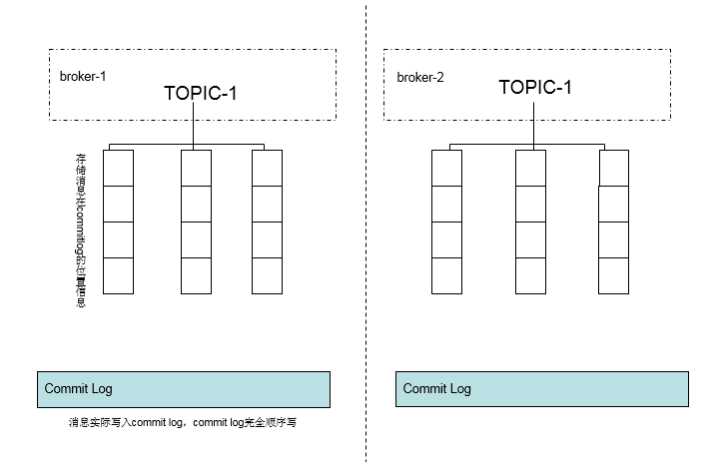
commit log
虽然每个topic下面有很多message queue,但是message queue本身并不存储消息。真正的消息存储会写在CommitLog的文件,message queue只是存储CommitLog中对应的位置信息,方便通过message queue找到对应存储在CommitLog的消息。
不同的topic,message queue都是写到相同的CommitLog 文件,也就是说CommitLog完全的顺序写。
具体如下图:
Producer
Producer端,每个实例在发消息的时候,默认会轮询所有的message queue发送,以达到让消息平均落在不同的queue上。而由于queue可以散落在不同的broker,所以消息就发送到不同的broker下,如下图:

Consumer负载均衡
集群模式
在集群消费模式下,每条消息只需要投递到订阅这个topic的Consumer Group下的一个实例即可。RocketMQ采用主动拉取的方式拉取并消费消息,在拉取的时候需要明确指定拉取哪一条message queue。
而每当实例的数量有变更,都会触发一次所有实例的负载均衡,这时候会按照queue的数量和实例的数量平均分配queue给每个实例。
默认的分配算法是AllocateMessageQueueAveragely,如下图:

还有另外一种平均的算法是AllocateMessageQueueAveragelyByCircle,也是平均分摊每一条queue,只是以环状轮流分queue的形式,如下图:

需要注意的是,集群模式下,queue都是只允许分配只一个实例,这是由于如果多个实例同时消费一个queue的消息,由于拉取哪些消息是consumer主动控制的,那样会导致同一个消息在不同的实例下被消费多次,所以算法上都是一个queue只分给一个consumer实例,一个consumer实例可以允许同时分到不同的queue。
通过增加consumer实例去分摊queue的消费,可以起到水平扩展的消费能力的作用。而有实例下线的时候,会重新触发负载均衡,这时候原来分配到的queue将分配到其他实例上继续消费。
但是如果consumer实例的数量比message queue的总数量还多的话,多出来的consumer实例将无法分到queue,也就无法消费到消息,也就无法起到分摊负载的作用了。所以需要控制让queue的总数量大于等于consumer的数量。
广播模式
由于广播模式下要求一条消息需要投递到一个消费组下面所有的消费者实例,所以也就没有消息被分摊消费的说法。
在实现上,其中一个不同就是在consumer分配queue的时候,会所有consumer都分到所有的queue。

版权说明 : 本文为转载文章, 版权归原作者所有 版权申明
原文链接 : https://blog.csdn.net/guolong1983811/article/details/78821879
内容来源于网络,如有侵权,请联系作者删除!