文章15 | 阅读 6246 | 点赞0
ITEXT 表格的指定列合并
问题场景
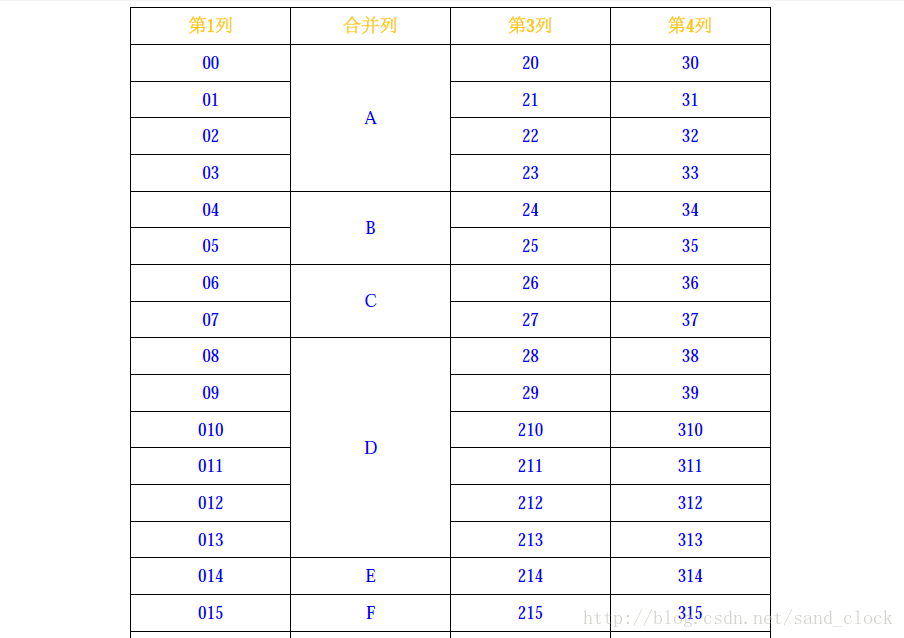
最近做一个项目的升级,用的是itext写PDF报告,对于一个表格,要求某一列按照值的本身是否重复来合并行。
CODE
需要导入的包:itext-pdfa-5.5.6.jar、itext-xtra-5.5.6.jar、itext-5.5.6.jar、itext-asian.jar
package itext;
import com.itextpdf.text.*;
import com.itextpdf.text.pdf.BaseFont;
import com.itextpdf.text.pdf.PdfPCell;
import com.itextpdf.text.pdf.PdfPTable;
import com.itextpdf.text.pdf.PdfWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Set;
/** * Created on 2017/6/9 * Author: youxingyang. */
public class RowSpanInTable {
public static void main(String[] args) throws Exception {
String fileName = "rowspan.pdf";
RowSpanInTable.testRowSpan(fileName);
}
private static void testRowSpan(String fileName)
throws IOException, DocumentException {
BaseFont bfCN = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", false);
// 正文的字体
Font headFont = new Font(bfCN, 12f, Font.BOLD, BaseColor.ORANGE);
Font textFont = new Font(bfCN, 12f, Font.NORMAL, BaseColor.BLUE);
Document document = new Document();
PdfWriter.getInstance(document, new FileOutputStream(fileName));
document.open();
//添加测试数据
List<String[]> list = new ArrayList<>();
for (int i = 0; i < 24; i++) {
String[] arr = new String[4];
String value;
if (i < 4) {
value = "A";
} else if (i >= 4 && i < 6) {
value = "B";
} else if (i >= 6 && i < 8) {
value = "C";
} else if (i >= 8 && i < 14) {
value = "D";
} else if (i >= 14 && i < 15) {
value = "E";;
} else if (i == 15) {
value = "F";
} else {
value = "G";
}
arr[0] = "0" + i;
arr[1] = value;
arr[2] = "2" + i;
arr[3] = "3" + i;
list.add(arr);
}
//建立一个4列的表格
PdfPTable table = new PdfPTable(4);
//计算'合并列'的合并相关集合
List<Integer> indexs;
//每个'合并列'的初始下标集合
List<Integer> spanStartIndex;
//每个'合并列'的合并数量集合
List<Integer> spanNumList;
//取出'合并列'的所有数据计算
List<String> ListIn = new ArrayList<>();
for (String[] aList : list) {
ListIn.add(aList[1]);
}
spanNumList = getSpanNumList(ListIn);
spanStartIndex = getStartIndexList(ListIn, spanNumList);
indexs = getIndexs(list, spanNumList, spanStartIndex);
//加表格头部
String[] titleArr = {"第1列", "合并列", "第3列", "第4列"};
addTitle(table, titleArr, headFont);
//加表格内容
addContent(table, list, textFont, spanNumList, spanStartIndex, indexs);
document.add(table);
document.close();
}
private static void addContent(PdfPTable table, List<String[]> list, Font textFont,
List<Integer> spanNumList, List<Integer> spanStartIndex, List<Integer> indexs) {
//表格数据内容
for (int i = 0; i < list.size(); i++) {
String[] str = list.get(i);
//第1列
Paragraph paragraph01 = new Paragraph(str[0], textFont);
paragraph01.setAlignment(1);
PdfPCell cell = new PdfPCell();
cell.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
cell.setVerticalAlignment(PdfPCell.ALIGN_MIDDLE);//然并卵
cell.setPaddingTop(-2f);//把字垂直居中
cell.setPaddingBottom(8f);//把字垂直居中
cell.addElement(paragraph01);
table.addCell(cell);
//合并列
Paragraph paragraph02 = new Paragraph(str[1], textFont);
paragraph02.setAlignment(1);
PdfPCell cell1 = new PdfPCell();
cell1.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
cell1.setVerticalAlignment(PdfPCell.ALIGN_MIDDLE);//然并卵
cell1.setPaddingTop(-2f);//把字垂直居中
cell1.setPaddingBottom(8f);//把字垂直居中
cell1.addElement(paragraph02);
setRowsSpan(indexs, spanStartIndex, spanNumList, table, cell1, i);
//第3列
Paragraph paragraph03 = new Paragraph(str[2], textFont);
paragraph03.setAlignment(1);
PdfPCell cell2 = new PdfPCell();
cell2.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
cell2.setVerticalAlignment(PdfPCell.ALIGN_MIDDLE);//然并卵
cell2.setPaddingTop(-2f);//把字垂直居中
cell2.setPaddingBottom(8f);//把字垂直居中
cell2.addElement(paragraph03);
table.addCell(cell2);
//第4列
Paragraph paragraph04 = new Paragraph(str[3], textFont);
paragraph04.setAlignment(1);
PdfPCell cell3 = new PdfPCell();
cell3.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
cell3.setVerticalAlignment(PdfPCell.ALIGN_MIDDLE);//然并卵
cell3.setPaddingTop(-2f);//把字垂直居中
cell3.setPaddingBottom(8f);//把字垂直居中
cell3.addElement(paragraph04);
table.addCell(cell3);
}
}
/** * 设置恰当位置的setRowSpan属性 * @param indexs 不加单元格的索引集合 * @param spanStartIndex 要加的单元格开始索引集合 * @param spanNumList 要加的单元格合并的值集合 * @param table table * @param cell cell * @param i 索引 */
private static void setRowsSpan(List<Integer> indexs, List<Integer> spanStartIndex,
List<Integer> spanNumList, PdfPTable table, PdfPCell cell, int i) {
if (indexs != null) {
Boolean isAllNotEqual = true;
for (Integer index : indexs) {
if (i == index) {
isAllNotEqual = false;
}
}
//没有不加的下标
if (isAllNotEqual) {
//判断在哪里设置span值
if (spanStartIndex != null) {
Boolean isSpan = false;
int copyJ = 0;
for (int j = 0; j < spanStartIndex.size(); j++) {
if (i == spanStartIndex.get(j)) {
isSpan = true;
copyJ = j;
break;
}
}
if (isSpan) {
int spanNum = spanNumList.get(copyJ);
cell.setRowspan(spanNum);
}
}
table.addCell(cell);
}
} else {
table.addCell(cell);
}
}
private static void addTitle(PdfPTable table, String[] titleArr, Font headFont) {
for (String aTitleArr : titleArr) {
Paragraph p = new Paragraph(aTitleArr, headFont);
PdfPCell cell = new PdfPCell();
p.setAlignment(1);
cell.setHorizontalAlignment(PdfPCell.ALIGN_CENTER);
cell.setVerticalAlignment(PdfPCell.ALIGN_MIDDLE);//然并卵
cell.setPaddingTop(-2f);//把字垂直居中
cell.setPaddingBottom(8f);//把字垂直居中
cell.addElement(p);
table.addCell(cell);
}
}
/** * 获取某列要合并的单元格数量 * @param list 内容必须符合'A,A,B,C,D,D,D,E' 而不是 'A,A,B,C,A,D,D,D,E' ,即所有相同的值必须在一起不能分散 * @return */
private static List<Integer> getSpanNumList(List<String> list) {
LinkedHashMap<String,Integer> map = new LinkedHashMap <>();
if(list.size() > 0) {
for (int i = 0; i < list.size(); i = i + 1) {
map.put(list.get(i), i);
}
}
//修改对应key值的value
Set<String> s = map.keySet();//获取KEY集合
List<String> strings = new ArrayList<>(s);
int spanNum = 0;
for (String string : strings) {
int tmpSpanNum = map.get(string) - spanNum + 1;
map.put(string, tmpSpanNum);
spanNum += tmpSpanNum;
}
List<Integer> res = new ArrayList<>();
for (String string : strings) {
res.add(map.get(string));
}
return res;
}
/** * 获取某列要合并的单元格初始下标 * @param list 内容必须符合'A,A,B,C,D,D,D,E' 而不是 'A,A,B,C,A,D,D,D,E' ,即所有相同的值必须在一起不能分散 * @param resSpanNumList * @return */
private static List<Integer> getStartIndexList(List<String> list, List<Integer> resSpanNumList) {
LinkedHashMap <String,Integer> map = new LinkedHashMap <>();
if(list.size() > 0) {
for (int i = 0; i < list.size(); i = i + 1) {
map.put(list.get(i), i);
}
}
Set<String> keys = map.keySet();//获取KEY集合
List<String> stringKeys = new ArrayList<>(keys);
List<Integer> res = new ArrayList<>();
if (stringKeys.size() == resSpanNumList.size()) {
for(int i = 0; i < stringKeys.size(); i++){
res.add(map.get(stringKeys.get(i)) - resSpanNumList.get(i) + 1);
}
}
return res;
}
/** * 不加某字段的索引集合 * @param list * @param resSpanNumList * @param resStartIndexList * @return */
private static List<Integer> getIndexs(List<String[]> list,
List<Integer> resSpanNumList, List<Integer> resStartIndexList) {
List<Integer> indexs = new ArrayList<>();
for (int i = 0; i < list.size(); i++) {
for (int j = 0; j < resStartIndexList.size(); j++) {
if (i == resStartIndexList.get(j)) {
for (int k = i + 1; k < i + resSpanNumList.get(j); k++) {
indexs.add(k);
}
}
}
}
return indexs;
}
}效果
版权说明 : 本文为转载文章, 版权归原作者所有 版权申明
原文链接 : https://blog.csdn.net/sand_clock/article/details/72957170
内容来源于网络,如有侵权,请联系作者删除!