文章15 | 阅读 6236 | 点赞0
ITEXT 目录生成的第二种方法
---最近在用itext写pdf报告,期间遇到目录生成的问题,而目录生成我认为最关键的是获取章节的页码问题。下面分别介绍这两种方法。除了这两种方法之外,还可以参考我的另一篇博客:ITEXT 目录生成的第三种方法
---前言:为了能唯一定位每个章节的页码,章节都是通过图片贴在PDF上的,即正文里的目录章节内容是图片格式。
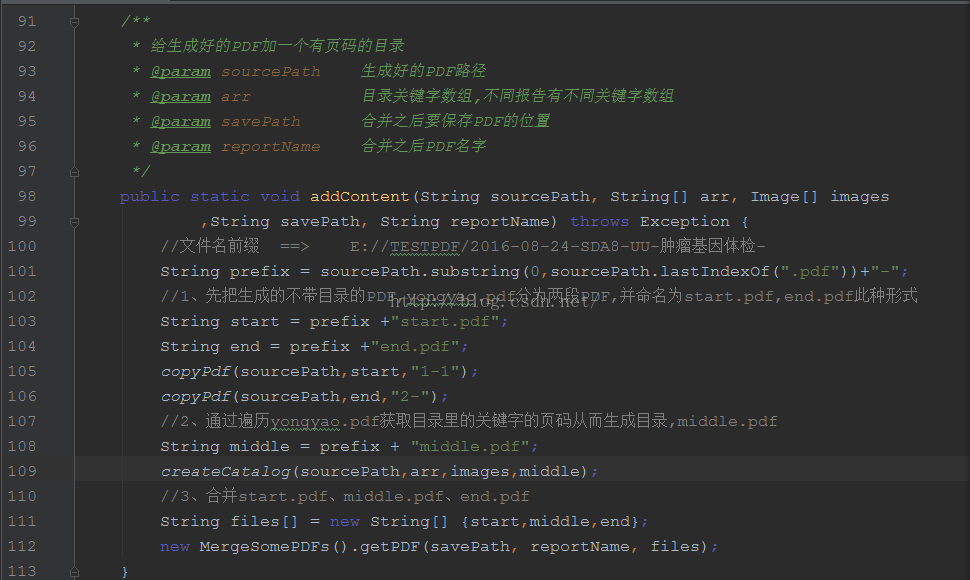
---方法一:
-------1、先生成不带目录的PDF文件,命名为a.pdf。假设此时目录应该在第3页,分别从a.pdf中截取pdf文件,分别命名为a-start.pdf、a-end.pdf。
-------2、遍历a.pdf获取目录章节的页码。命名为a-middle.pdf。
-------3、合并a-start.pdf、a-middle.pdf、a-end.pdf三个PDF。
-------复杂度:O(M*N) M为a.pdf页数、N为目录中章节的数目。
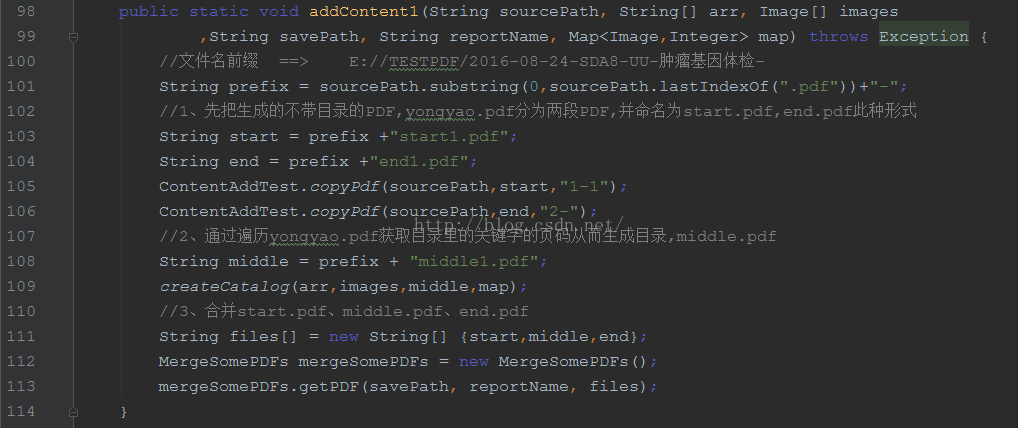
---方法二:
-------1、先生成不带目录的PDF文件,并用Map记录目录中章节出现的页码,命名为a.pdf。假设此时目录应该在第3页,分别从a.pdf中截取pdf文件,分别命名为a-start.pdf、a-end.pdf。
-------2、直接从Map集合中获取目录章节的页码。命名为a-middle.pdf。
-------3、合并a-start.pdf、a-middle.pdf、a-end.pdf三个PDF。
-------复杂度:O(N) M为a.pdf页数、N为目录中章节的数目。

-------分析:第二种方法本质上利用空间换时间来减少时间复杂度。具体源码详见itext生成目录源码
版权说明 : 本文为转载文章, 版权归原作者所有 版权申明
原文链接 : https://blog.csdn.net/sand_clock/article/details/52469904
内容来源于网络,如有侵权,请联系作者删除!